A Beginner's Guide to Machine Learning Operations (MLOps) Workflow

Machine Learning Operations (MLOps) is a set of practices that aim to deploy and maintain machine learning models, including Large Language Models (LLMs), in production reliably and efficiently.
This emerging discipline addresses the challenges of operationalizing machine learning and focuses on the collaboration between data scientists and operations teams. MLOps integrates the principles of DevOps with the specific requirements of machine learning, facilitating the seamless development, deployment, and monitoring of models.
In this guide, we will provide an overview of the MLOps workflow, detailing each stage from data collection to model monitoring. Whether you are a data scientist, software engineer, or IT professional, understanding MLOps is crucial for building robust machine learning systems that can adapt to changing environments and requirements.
Table of Contents
- Data Collection and Preparation
- Model Training and Validation
- Model Deployment
- Continuous Integration and Continuous Deployment (CI/CD) for ML
- Monitoring and Maintenance
- Challenges and Best Practices in MLOps
- Popular Software Tools for MLOps
- How to Get Started with MLOps
- Beginner's Guide to Machine Learning Operations
Data Collection and Preparation
Data collection and preparation form the foundation of any machine learning project. This stage involves gathering raw data from various sources, cleaning it, and transforming it into a format suitable for analysis. The quality of the data directly impacts the performance of the machine learning models, making this step critical. For example, FolioProjects is a data lake specialized in collecting project management data from various popular sources for analysis my ML LLMs and transfer further down the line to data warehouses
In general, data collection can involve scraping data from websites, using APIs, or accessing databases. Once the data is collected, it undergoes preprocessing, which includes handling missing values, removing duplicates, and normalizing the data. Feature engineering is another crucial aspect, where new features are created from the existing data to enhance the model's predictive power.
Data preparation also involves splitting the data into training, validation, and test sets. This ensures that the model is evaluated on unseen data, providing a realistic measure of its performance. Effective data management and versioning practices are essential to maintain the integrity and reproducibility of the data pipeline.
Model Training and Validation
Once the data is prepared, the next step is model training and validation. During model training, machine learning algorithms learn patterns from the training data. This process involves selecting an appropriate algorithm, tuning hyperparameters, and iteratively improving the model's performance.
Validation is a critical step where the trained model is evaluated on a separate validation set. This helps in assessing the model's generalization capability and avoiding overfitting. Cross-validation techniques, such as k-fold cross-validation, are often employed to obtain a more reliable estimate of the model's performance.
Model training and validation require a robust computational infrastructure, especially for large datasets and complex models like LLMs. Leveraging cloud-based platforms and distributed computing can significantly speed up this process. Additionally, tools like TensorFlow and PyTorch provide frameworks for efficient model development and experimentation.
Model Deployment
Model deployment is the process of integrating the trained model into a production environment where it can make predictions on new data. This stage involves several steps, including model serialization, creating an API endpoint, and integrating with existing systems.
Deployment can be challenging due to the need for scalability, low latency, and high availability. Containerization technologies like Docker, along with orchestration tools like Kubernetes, are commonly used to manage and scale machine learning models in production environments. Additionally, serverless architectures can provide cost-effective solutions for deploying models with sporadic usage patterns.
Ensuring the model's reliability and performance in production requires thorough testing, including unit tests, integration tests, and end-to-end tests. Continuous monitoring is also essential to detect any performance degradation or issues that may arise after deployment.
Continuous Integration and Continuous Deployment (CI/CD) for ML
Continuous Integration and Continuous Deployment (CI/CD) are critical practices in MLOps that automate the building, testing, and deployment of machine learning models. CI/CD pipelines enable teams to rapidly iterate on their models and ensure that changes are consistently and reliably integrated into the production environment.
In a typical CI/CD pipeline for machine learning, the process begins with the automated building and testing of code. This includes unit tests for individual components, integration tests for combined components, and validation tests for the entire model. Once the tests pass, the model is packaged and deployed to the production environment.
CI/CD pipelines also facilitate version control and rollback capabilities, ensuring that previous versions of the model can be restored if necessary. Tools like Jenkins, GitLab CI, and CircleCI provide robust solutions for implementing CI/CD pipelines in machine learning projects.
Monitoring and Maintenance
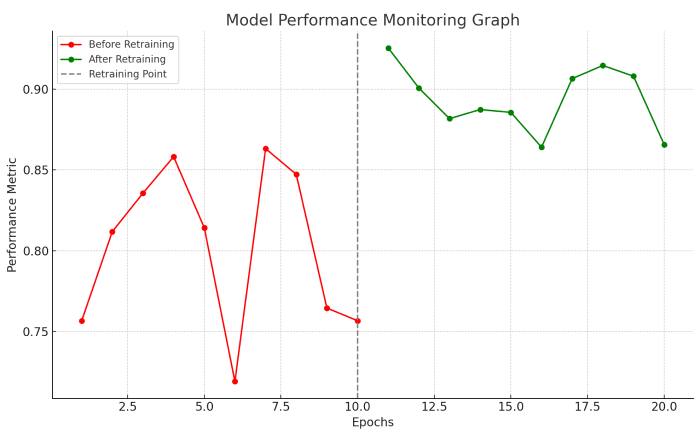
Monitoring and maintenance are ongoing activities that ensure the deployed model continues to perform as expected. This involves tracking various performance metrics, such as accuracy, latency, and throughput, as well as monitoring for data drift and model degradation.
Data drift occurs when the statistical properties of the input data change over time, leading to a decline in model performance. Regularly retraining the model on new data can help mitigate this issue. Additionally, setting up alerts and automated retraining pipelines can ensure that the model remains up-to-date with the latest data.
Maintenance also includes addressing any infrastructure issues, updating dependencies, and ensuring compliance with regulatory requirements. Effective monitoring and maintenance practices are crucial for sustaining the long-term performance and reliability of machine learning models in production.
Challenges and Best Practices in MLOps
Implementing MLOps comes with its own set of challenges, including managing the complexity of machine learning pipelines, ensuring reproducibility, and handling the diverse skill sets required. However, several best practices can help overcome these challenges.
One of the key best practices is to adopt a modular approach to building machine learning pipelines. This involves breaking down the pipeline into smaller, reusable components that can be independently developed, tested, and deployed. Additionally, using version control for both code and data ensures reproducibility and traceability.
Collaboration between data scientists, software engineers, and operations teams is crucial for the success of MLOps. Establishing clear communication channels and fostering a culture of collaboration can help address the interdisciplinary challenges of machine learning projects. Investing in automation and tooling can also significantly enhance the efficiency and reliability of MLOps workflows.
Popular Software Tools for MLOps
Several software tools have been developed to streamline MLOps workflows, each offering unique features to address different aspects of the machine learning lifecycle. Here are some popular tools commonly used in the industry:
-
Kubeflow: An open-source platform designed to simplify machine learning workflows on Kubernetes. Kubeflow provides components for model training, serving, and monitoring, making it a comprehensive solution for managing ML pipelines.
-
MLflow: An open-source platform that helps manage the end-to-end machine learning lifecycle. MLflow includes modules for tracking experiments, packaging code into reproducible runs, and sharing and deploying models.
-
TensorFlow Extended (TFX): A production-ready machine learning platform that enables scalable and high-performance machine learning tasks. TFX provides components for data validation, model analysis, and serving.
-
Azure Machine Learning: A cloud-based service by Microsoft that offers tools for data preparation, model training, and deployment. It integrates seamlessly with other Azure services, providing a robust environment for MLOps.
-
Amazon SageMaker: A fully managed service by AWS that provides tools for building, training, and deploying machine learning models. SageMaker simplifies the MLOps workflow with features like automated model tuning and monitoring.
These tools can be used individually or in combination to create a customized MLOps pipeline that meets the specific needs of your organization. Choosing the right tools depends on factors like the complexity of your projects, the skills of your team, and your existing infrastructure.
How to Get Started with MLOps
Getting started with MLOps involves a series of steps that lay the foundation for efficient and scalable machine learning operations. Here’s a roadmap to help you begin your MLOps journey:
-
Understand the Basics: Before diving into MLOps, it’s essential to have a solid understanding of machine learning concepts and DevOps principles. Familiarize yourself with the key stages of the machine learning lifecycle, such as data collection, model training, and deployment.
-
Build a Cross-Functional Team: MLOps requires collaboration between data scientists, software engineers, and operations professionals. Assemble a team with diverse skill sets and establish clear communication channels to facilitate collaboration.
-
Choose the Right Tools: Based on your project requirements and team expertise, select the appropriate MLOps tools. Start with widely used platforms like Kubeflow, MLflow, or TFX, and gradually integrate more specialized tools as needed.
-
Develop Reproducible Pipelines: Create modular and reusable machine learning pipelines that can be easily reproduced and shared across the team. Use version control for both code and data to ensure consistency and traceability.
-
Implement CI/CD Pipelines: Set up CI/CD pipelines to automate the building, testing, and deployment of your models. This will enable you to iterate quickly and deploy models reliably into production.
-
Monitor and Maintain Models: Establish monitoring practices to track the performance of your deployed models. Set up alerts for any anomalies or performance degradation and implement automated retraining pipelines to keep your models up-to-date.
-
Stay Updated: The field of MLOps is rapidly evolving, with new tools and best practices emerging regularly. Stay informed by following industry blogs, attending conferences, and participating in online communities.
Starting with MLOps can be challenging, but by following these steps and leveraging the right resources, you can build a robust and scalable machine learning operation that delivers consistent value.
Beginner's Guide to Machine Learning Operations
Machine Learning Operations (MLOps) is a vital discipline that bridges the gap between machine learning development and production deployment.By understanding the MLOps workflow, from data collection to model monitoring, organizations can build and maintain robust machine learning systems that deliver consistent value.
FolioProjects is a no-code project management focused data lake. It's focused on helping organizations to analyze their projects in various ways, including MLOps workflows. Towards this goal, the platform is designed to make processes like data workflow orchestration (MLflow + MLOps) easy for project management data.
Regardless of industry, adopting best practices and leveraging the right tools can help navigate the complexities of MLOps and ensure the successful deployment and maintenance of machine learning models.

